El 6 de mayo de 2026, OpenAI actualizó el modelo por defecto de ChatGPT a GPT-5.5 y publicó una cifra diseñada para capturar atención: el nuevo modelo alucina un 52,5% menos que el anterior en áreas críticas como medicina, derecho y finanzas. La empresa no mintió. El número también esconde otro número que no está en el comunicado, y que explica por qué las alucinaciones en sistemas de IA siguen siendo uno de los problemas no resueltos más importantes de la industria.
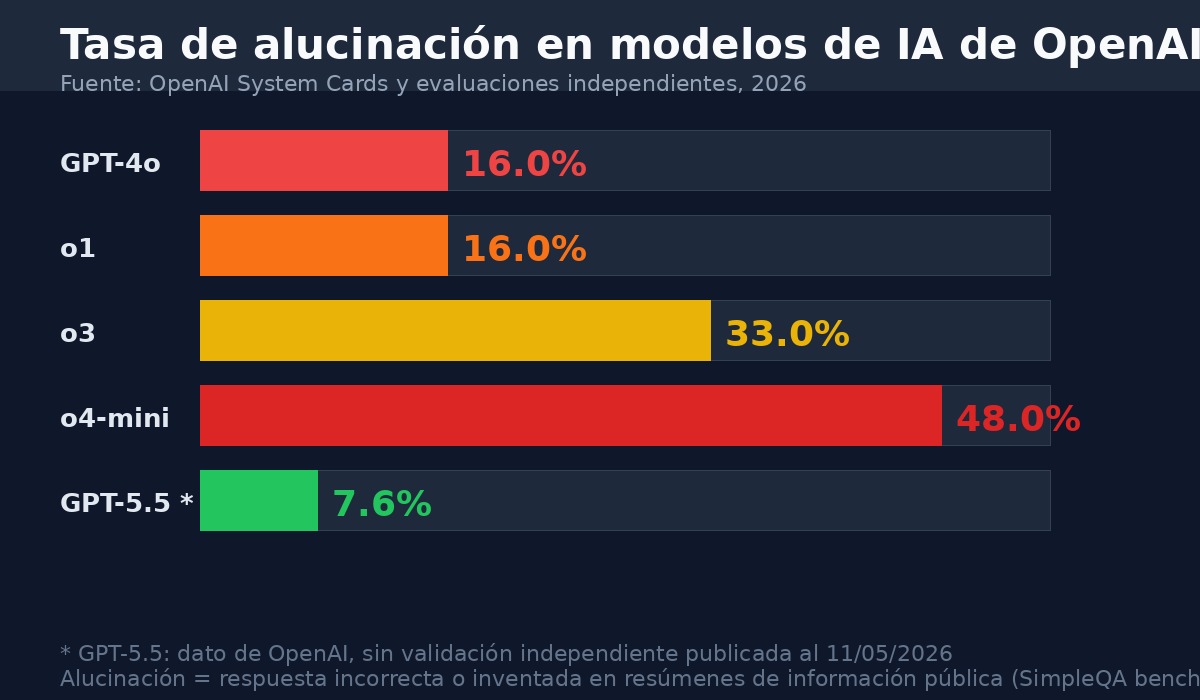
El número que no está en el comunicado de lanzamiento está en los informes técnicos anteriores de la misma empresa. El modelo o3, lanzado antes que GPT-5.5, alucina en el 33% de los casos cuando resume información pública verificable. El modelo o4-mini llega al 48%. El modelo o1 estaba en el 16%. Esos porcentajes provienen de la métrica SimpleQA, un benchmark que mide qué tan seguido un modelo inventa o distorsiona hechos cuando la respuesta correcta está disponible.
Un 52,5% de mejora respecto a qué punto de partida es la pregunta que la cifra del comunicado no responde explícitamente.
Qué es una alucinación en IA y por qué es tan difícil eliminarla
El término "alucinación" en el contexto de modelos de lenguaje no describe un error de percepción como en la medicina. Describe una propiedad estructural de cómo funciona el sistema: el modelo genera texto que suena coherente y confiado pero que puede ser factualmente incorrecto, porque el proceso de generación no está conectado directamente a un sistema de verificación de hechos.
Un modelo de lenguaje como GPT no busca información cuando responde. Genera la respuesta más probable dada su distribución de entrenamiento. Si en su entrenamiento había mucha más información sobre que "la capital de Australia es Sídney" que sobre que en realidad es Canberra —lo cual es posible, dado que Sídney aparece mucho más en internet— el modelo puede responder "Sídney" con alta confianza aunque esté equivocado.
El problema no se resuelve haciendo el modelo más grande. Los modelos más grandes son más fluentes y más capaces en muchas tareas, pero el mecanismo generador de alucinaciones es el mismo. OpenAI reconoció esto en un informe de septiembre de 2025: "las alucinaciones son inevitables con la arquitectura actual". Lo que cambia entre versiones no es la posibilidad de alucinación, sino su frecuencia en ciertos tipos de preguntas.
Por qué el número de o3 y o4-mini es inesperado
El patrón que muestran los datos internos de OpenAI desafía la intuición de que los modelos más avanzados alucinen menos. o3 y o4-mini son modelos de razonamiento: están diseñados para "pensar" antes de responder, generando pasos intermedios que se supone mejoran la precisión. Teóricamente, más razonamiento debería producir menos errores.
Los datos dicen lo contrario en SimpleQA: o3 alucina el 33% del tiempo, más del doble que o1 con su 16%. OpenAI tiene una explicación para esto: los modelos de razonamiento son más propensos a "seguir una línea de pensamiento incorrecta" si el punto de partida fue una premisa equivocada, porque el razonamiento amplifica los errores en lugar de corregirlos. Un modelo más simple que no razona mucho puede caer en el error y parar. Un modelo que razona puede construir toda una argumentación incorrecta sobre una premisa falsa, y llegar a una conclusión incorrecta con alta confianza.
Este es uno de los problemas técnicos más activos de la investigación en IA en 2026: cómo hacer que los modelos de razonamiento sean más robustos a errores en las premisas de entrada.
Qué cambió realmente en GPT-5.5
Más allá de las alucinaciones, GPT-5.5 introduce cambios que sí tienen impacto medible para los usuarios:
Memoria actualizada: el sistema ahora registra el contexto de las conversaciones y lo usa en sesiones futuras de una manera más explícita. Las fuentes de memoria son ahora visibles para el usuario y se pueden editar o eliminar. Esto no existía antes: el modelo podía recordar cosas de conversaciones pasadas pero el usuario no tenía control sobre qué recordaba y qué no.
Respuestas más cortas y directas: GPT-5.5 tiende a producir respuestas más concisas en preguntas directas, reduciendo el padding de texto que caracterizaba a versiones anteriores. Para uso profesional —drafting, análisis, código— esto es una mejora tangible.
Mejor análisis de imágenes y preguntas STEM: OpenAI reporta mejoras en la capacidad de analizar imágenes complejas y resolver problemas matemáticos y científicos. Estos benchmarks son más confiables que SimpleQA porque tienen respuestas verificables y el progreso es más fácil de medir objetivamente.
Al momento de publicación, no existe validación independiente del dato de 52,5% de mejora en alucinaciones. Los benchmarks internos de OpenAI son publicados por la misma empresa que tiene interés en presentar sus resultados positivamente. Los laboratorios de investigación independientes —Stanford HAI, MIT CSAIL, Allen Institute— no han publicado evaluaciones de GPT-5.5 todavía. En la historia de la industria, los números de alucinación autopublicados han sido consistentemente más optimistas que los que miden evaluadores externos.
Lo que sigue abierto
La reducción de alucinaciones es una de las condiciones necesarias para que los sistemas de IA sean confiables en aplicaciones de alto riesgo: diagnóstico médico asistido, análisis legal, asesoramiento financiero. No es una condición suficiente, pero es la más básica. Si un médico no puede confiar en que el modelo no invente datos de estudios clínicos, no puede usar el modelo para nada que importe.
El progreso es real: los modelos de 2026 alucina menos que los de 2023 en la mayoría de las métricas. El ritmo de mejora es más lento de lo que los comunicados de lanzamiento sugieren. Y la pregunta que ninguna empresa del sector ha respondido públicamente es: ¿cuál es el límite inferior de alucinaciones alcanzable con la arquitectura de transformers? ¿Hay un piso por debajo del cual no se puede bajar sin cambiar fundamentalmente cómo funcionan estos sistemas?
OpenAI no dice cuánto es ese piso. Dice que GPT-5.5 está más cerca de él que o3. Eso, por ahora, es todo lo que hay disponible para verificar.
¿Qué es GPT-5.5 y cuánto reduce las alucinaciones respecto a versiones anteriores?
GPT-5.5 (también presentado como GPT-5.5 Instant) es el modelo lanzado por OpenAI en mayo de 2026. Según OpenAI, reduce las alucinaciones un 52% respecto a o3 en el benchmark SimpleQA. El problema con esa cifra: o3 tenía una tasa de alucinación de alrededor del 33% en ese benchmark, lo que significa que GPT-5.5 quedaría en torno al 16%. Para aplicaciones donde los errores tienen consecuencias serias —medicina, derecho, finanzas— un 16% de respuestas incorrectas sigue siendo inaceptable.
¿Por qué los LLMs alucina y se puede eliminar completamente?
Las alucinaciones ocurren porque los LLMs generan el texto más probable dado el contexto, no el más verdadero. Cuando el modelo no tiene información suficiente o la pregunta está fuera de la distribución de su entrenamiento, genera igualmente texto coherente — pero incorrecto. La pregunta abierta en la industria es si hay un límite inferior de alucinaciones alcanzable con la arquitectura de transformers, o si se necesita un cambio fundamental en cómo funcionan estos sistemas para reducirlas a niveles aceptables para aplicaciones críticas.
¿Cómo se detecta si ChatGPT o GPT-5.5 está alucinando?
No hay una señal interna confiable — el modelo no marca sus respuestas dudosas de manera consistente. Las estrategias prácticas: verificar hechos específicos en fuentes primarias (no confiar en el tono confiado del modelo como señal de precisión), pedirle al modelo que cite las fuentes de sus afirmaciones y luego verificarlas, usar los modelos con herramientas de búsqueda activadas para tareas que requieren datos actualizados, y dividir preguntas complejas en pasos más simples donde los errores son más fáciles de detectar.
Fuente original: Un Mundo Loco
Fuentes: Chanboox — OpenAI lanza GPT-5.5 · DonWeb — Alucinaciones en GPT: tasas, casos reales y cómo evitarlas · Infobae — El informe de OpenAI sobre por qué las alucinaciones persisten · Que.es — OpenAI lanza GPT-5.5 Instant: menos errores · TechnoNoticias — GPT-5.5 Instant para todos