Hay una pregunta que vale hacerse antes de usar cualquier herramienta de IA: ¿qué está haciendo exactamente esta cosa? La respuesta no requiere matemáticas. Requiere entender un mecanismo básico que, una vez comprendido, explica por qué ChatGPT hace bien algunas cosas y falla de formas muy específicas en otras.
Los modelos de lenguaje grande —LLMs, por Large Language Models— son sistemas de inteligencia artificial entrenados para predecir texto. Esa es la tarea base, la que todo lo demás construye: dado un texto de entrada, ¿qué texto tiene más probabilidad de venir a continuación?
ChatGPT, Claude, Gemini, Llama, DeepSeek, Mistral: todos son LLMs. Distintos tamaños, distintos datos de entrenamiento, distintas decisiones de diseño. El mecanismo central es el mismo.
Cómo aprenden
El entrenamiento de un LLM tiene dos fases principales.
Preentrenamiento. El modelo procesa cantidades masivas de texto: libros, páginas web, código, artículos científicos, redes sociales, manuales técnicos. La tarea de aprendizaje es simple: dado un fragmento de texto con la última parte oculta, predecir qué va a continuación. El modelo se equivoca, se corrige, se equivoca de nuevo, se corrige de nuevo, millones de veces.
Lo que aprende en ese proceso es estadística del lenguaje: qué palabras aparecen juntas, qué estructuras gramaticales son comunes, qué tipo de respuesta sigue a qué tipo de pregunta, qué nombres propios aparecen con qué contextos. No "entiende" en el sentido que lo entendemos los humanos — aprende patrones en la forma en que los humanos usan el lenguaje.
Ajuste fino con feedback humano (RLHF). Después del preentrenamiento, el modelo se ajusta para que sus respuestas sean más útiles, más honestas y menos dañinas. Humanos califican distintas respuestas y ese feedback se usa para ajustar el modelo. Aquí es donde se instalan las instrucciones sobre cómo comportarse, qué decir y qué no decir.
Por qué "alucina"
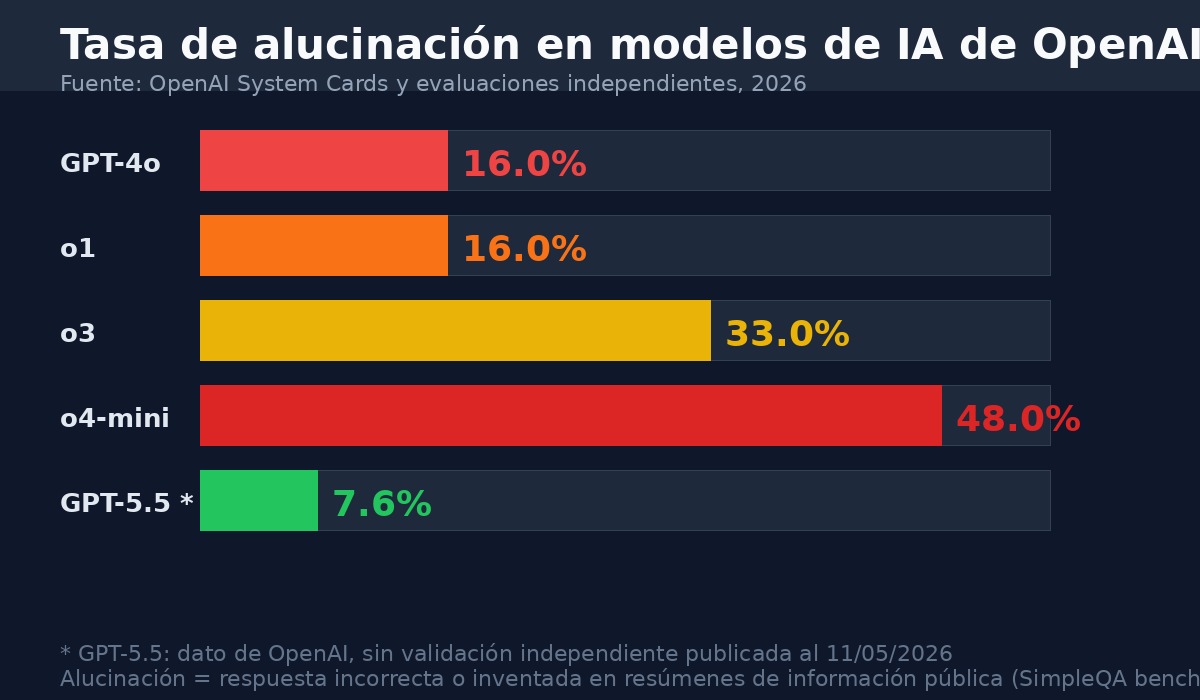
Las alucinaciones — respuestas convincentes pero falsas — son el problema más conocido de los LLMs. Entender por qué ocurren requiere entender el mecanismo.
El modelo no tiene una base de datos de hechos que consultar. No "sabe" que la Torre Eiffel está en París de la misma manera que una enciclopedia "sabe" eso. Lo que tiene es un patrón estadístico: el texto sobre la Torre Eiffel aparece consistentemente junto al texto sobre París. Cuando el modelo genera una respuesta, genera la respuesta que es estadísticamente más probable dado el contexto.
La mayoría del tiempo, eso funciona bien porque los hechos comunes tienen patrones estadísticos muy fuertes. Pero para hechos raros, recientes, muy específicos, o que contradicen los patrones habituales, el modelo puede generar texto que suena correcto pero no lo es.
La alucinación no es el modelo mintiendo. Es el modelo siendo fiel a su tarea (generar texto probable) en un caso donde lo probable y lo verdadero divergen.
Qué diferencia a los modelos grandes de los pequeños
"Grande" en LLM se refiere principalmente al número de parámetros: los valores numéricos que el modelo ajusta durante el entrenamiento. GPT-3 tenía 175 mil millones de parámetros. Los modelos más grandes actuales tienen varios trillones. Más parámetros permite capturar patrones más complejos y sutiles en el lenguaje.
Pero el tamaño no es el único factor. Los datos de entrenamiento importan: un modelo entrenado con datos más limpios y más diversos suele ser mejor que uno entrenado con más datos de menor calidad. El ajuste fino importa: un modelo ajustado para ser útil y honesto puede superar a uno más grande mal ajustado. La arquitectura importa: mejoras en el diseño interno del modelo pueden compensar la diferencia de parámetros.
Los modelos razonan, de cierta manera. Las versiones más recientes pueden "pensar en voz alta" antes de responder — generar pasos intermedios de razonamiento que mejoran la calidad de la respuesta final. Eso no es razonamiento en el sentido filosófico, pero produce resultados más confiables en problemas que requieren pasos encadenados.
Por qué son buenos en algunas tareas y malos en otras
Los LLMs son especialmente buenos en:
- Tareas donde el patrón estadístico del lenguaje es lo más importante: redacción, resumen, traducción, explicación
- Síntesis de información que aparece frecuentemente en su entrenamiento
- Código: los patrones del código fuente son muy regulares y el feedback de errores de compilación es muy claro
Son especialmente malos en:
- Hechos muy específicos o recientes que no están bien representados en el entrenamiento
- Aritmética compleja: el lenguaje natural no es el mejor substrato para operaciones matemáticas (por eso los modelos más avanzados usan herramientas externas para cálculo)
- Razonamiento espacial y físico, donde la intuición estadística del lenguaje no captura las restricciones del mundo real
- Reconocer los límites de su propio conocimiento: tienden a responder con confianza incluso cuando no saben
Lo que cambia todo esto
Entender que los LLMs predicen texto y no "piensan" tiene una consecuencia práctica: la forma en que uno los usa importa enormemente. Un prompt que da contexto claro, divide el problema en pasos y pide al modelo que revise su propia respuesta produce resultados sistemáticamente mejores que uno vago y abierto.
También cambia cómo uno evalúa las respuestas. Un LLM que responde con mucha confianza sobre un tema raro está haciendo exactamente lo que fue entrenado para hacer: generar texto probable. Eso no garantiza que el texto sea correcto.
La herramienta es poderosa. Entenderla hace que sea más útil y más segura de usar.
¿Qué es un LLM (Large Language Model) en términos simples?
Un LLM es un modelo de inteligencia artificial entrenado en enormes cantidades de texto para predecir qué palabra o fragmento de texto viene a continuación dado un contexto. "Grande" se refiere a la cantidad de parámetros (pesos del modelo) — los más avanzados tienen cientos de miles de millones. Lo que emergió de esa escala fue sorprendente: los modelos desarrollaron capacidades de razonamiento, traducción, programación y análisis que nadie predijo explícitamente. ChatGPT, Claude, Gemini y Llama son todos LLMs.
¿En qué se diferencia un LLM de una IA "que piensa"?
Un LLM no tiene representaciones internas del mundo, intenciones ni conciencia. Procesa tokens (fragmentos de texto) y genera el siguiente token más probable dado el contexto. Lo que parece "razonamiento" es una propiedad emergente del entrenamiento en texto humano, que incluye millones de ejemplos de razonamiento explícito. La diferencia práctica: los LLMs son mejores en tareas donde la respuesta correcta aparece frecuentemente en texto similar, y peores en tareas que requieren razonamiento físico o conocimiento fuera de la distribución de su entrenamiento.
¿Por qué los LLMs a veces inventan información con total confianza?
Porque generan el texto más probable dado el contexto, no el texto más verdadero. Si el contexto sugiere que viene una respuesta específica y segura, el modelo genera eso aunque no tenga base factual. Este fenómeno se llama "alucinación". La solución parcial es el uso de herramientas (búsqueda web, RAG), que proveen al modelo de información verificada en tiempo real. Pero el problema fundamental no desaparece: el modelo sigue prediciendo texto, ahora con mejor contexto.
Fuente original: Un Mundo Loco