La discusión sobre contenido generado por IA dejó de ser filosófica.
Hoy ya existe una carrera concreta por dejar marcas verificables en imágenes, audio y video para que cualquiera pueda saber si un contenido fue creado, editado o pasado por una herramienta de inteligencia artificial. Los nombres que están al frente de esa pelea son tres: Content Credentials, SynthID y C2PA.
Y lo importante no es sólo el nombre. Es que empresas rivales como OpenAI y Google ya están moviéndose en la misma dirección.
Qué cambió ahora
OpenAI anunció el 19 de mayo de 2026 que está fortaleciendo su sistema de procedencia de contenido con una estrategia de varias capas. Eso incluye:
- conformidad con C2PA;
- incorporación de SynthID de Google DeepMind para imágenes;
- y una vista previa de una herramienta pública para verificar si una imagen salió de OpenAI.
Google, por su parte, anunció casi al mismo tiempo que está expandiendo sus herramientas para entender cómo se creó y editó contenido en la web. En su propio ecosistema sumó verificación de C2PA Content Credentials y profundizó el uso de SynthID.
Eso significa algo simple: el mercado empezó a aceptar que no alcanza con generar contenido. También hace falta poder explicarlo.
Qué es C2PA
C2PA significa Coalition for Content Provenance and Authenticity.
Es un estándar abierto para incrustar información de procedencia en archivos digitales. En la práctica, funciona como una especie de historial verificable: qué software tocó el archivo, si fue creado por una cámara, editado después, reexportado o generado por una IA compatible.
No es una solución mágica. Pero sí es una base común.
Si un contenido pasa por herramientas que respetan el estándar, puede llevar metadatos confiables que sobreviven mejor que un simple nombre de archivo o una firma visual.
Qué hace SynthID
SynthID es otra cosa.
Es una marca de agua invisible desarrollada por Google DeepMind que se inserta directamente en el contenido generado por IA. A diferencia de los metadatos, que pueden borrarse o perderse, la idea es que la señal esté dentro de la propia imagen, audio, video o texto.
Google dice que ya ha marcado miles de millones de contenidos con SynthID y que la tecnología se expandió más allá de imágenes, hacia texto, audio y video.
La ventaja es obvia: una señal incrustada en el contenido puede ser más resistente que una etiqueta externa.
La desventaja también: ninguna señal es perfecta y no todo contenido va a conservarla después de una captura, una compresión agresiva o una edición posterior.
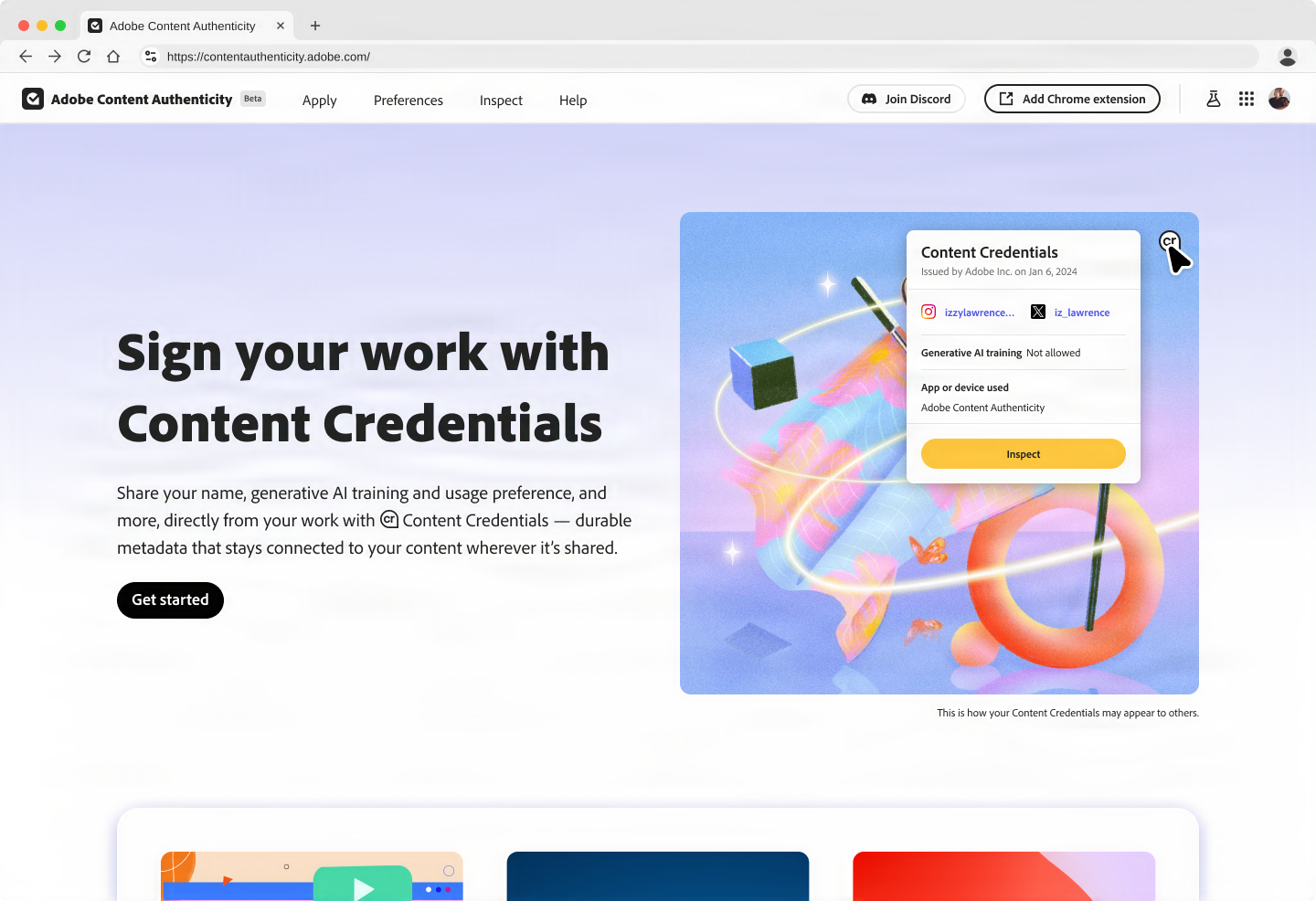
Qué son los Content Credentials
Los Content Credentials son la interfaz visible de ese sistema de procedencia.
Adobe los impulsa como una forma de asociar información de origen, edición y atribución a una pieza de contenido. En su ecosistema, ayudan a que una foto o una imagen generada o editada lleve una especie de ficha técnica legible por herramientas compatibles.
Para un usuario normal, eso puede aparecer como un pequeño indicador de autenticidad. Para un sistema, es una forma de leer el historial del archivo.
Por qué importa que OpenAI y Google se muevan juntos
Porque si cada empresa inventa su propio sello, el usuario no resuelve nada.
La pelea real es de interoperabilidad. Si una herramienta marca contenido, otra lo tiene que poder leer. Si un archivo salta entre plataformas, la señal no debería desaparecer al primer clic. Y si un medio, un navegador o una red social quiere mostrar contexto, necesita un lenguaje común.
Por eso el paso de OpenAI hacia C2PA y SynthID es importante: le da masa crítica a un esquema que, de otro modo, podría quedar encerrado en cada jardín privado.
Lo que resuelve y lo que no
Resuelve varias cosas útiles:
- ayuda a saber si una imagen fue creada o editada por una IA compatible;
- da contexto sobre el origen del contenido;
- facilita la atribución y la trazabilidad;
- y puede ayudar a medios, buscadores y plataformas a mostrar mejor el historial de un archivo.
Pero no resuelve todo:
- no garantiza verdad periodística;
- no prueba que una imagen sea real si fue capturada por una cámara;
- no impide que alguien quite señales o vuelva a exportar un archivo sin metadatos;
- y no detecta por sí solo todos los contenidos falsos.
En otras palabras: sirve mucho más como infraestructura de transparencia que como detector absoluto de fraude.
La conclusión incómoda
La industria ya asumió que el contenido generado por IA va a circular por todas partes.
La pregunta que sigue no es si hay que frenarlo todo. Es cómo se marca, cómo se verifica y cómo se evita que el caos de versiones, recortes y reposts convierta todo en una sopa ilegible.
Por eso esta noticia importa.
No porque un estándar vaya a salvar internet.
Sí porque, por primera vez, las grandes empresas de IA parecen estar de acuerdo en algo básico: el origen del contenido ya no es un detalle técnico. Es una parte central de la confianza.
Fuentes
- OpenAI: Advancing content provenance for a safer, more transparent AI ecosystem
- OpenAI Help Center: C2PA and SynthID in OpenAI-generated images
- Google: Tools to understand how content was created and edited
- Google: SynthID Detector
- C2PA: Content Credentials specification
- Adobe: Content Credentials / Content Authenticity





