En diciembre de 2024, un equipo integrado por Rupert Lane, Anthony Hay, Arthur Schwarz y Jeff Shrager logró volver a ejecutar la versión original de ELIZA, el programa que Joseph Weizenbaum desarrolló en MIT entre 1964 y 1966 y que suele ser considerado el primer chatbot. La restauración importa porque no reanimó una copia tardía ni una adaptación escolar: puso en marcha el código histórico sobre una reconstrucción de CTSS, el sistema de tiempo compartido de MIT, corriendo en un emulador de IBM 7094.
El dato más fuerte no está sólo en la fecha sino en la materialidad del rescate. El equipo trabajó con 53 páginas impresas, unas 2600 líneas de código en MAD, SLIP y ensamblador IBM; halló en 2021 un listado fechado en 1965 dentro de los papeles de Weizenbaum en MIT; encontró material adicional en 2023; y consiguió que el 96% de la restauración proviniera de archivos originales. El IBM 7094 sobre el que corría CTSS tenía 32 mil palabras de memoria de usuario, longitud de palabra de 36 bits, velocidad cercana a 450 kHz y soporte para unos 30 usuarios simultáneos.
El hallazgo en una carpeta fechada en 1965
Durante años se creyó que el código original de ELIZA estaba perdido. La situación cambió cuando David Berry sugirió buscar en los papeles de Joseph Weizenbaum y, en 2021, Jeff Shrager trabajó con el archivista Myles Crowley para revisar cajas del MIT Institute Archives. Allí apareció una carpeta fechada en 1965 con un listado de la fuente y dos versiones preliminares del guion DOCTOR.
Ese detalle altera bastante la historia conocida. Hasta entonces, la mayoría de las personas que “probaban ELIZA” en realidad estaban usando versiones derivadas, clones o reescrituras. El hallazgo permitió separar la leyenda del objeto técnico y ver qué había escrito realmente Weizenbaum para sostener una conversación por terminal.
En 2023, Berry y Shrager regresaron al archivo y encontraron más código de soporte en SLIP. Recién con esa segunda búsqueda el conjunto quedó cerca de ser ejecutable. La recuperación dependió de un trabajo de arqueología del software: seguir papeles incompletos, reconstruir dependencias y entender un ecosistema de programación que ya no existe en uso cotidiano.
La máquina que hizo posible una conversación
ELIZA no habría existido sin CTSS. Introducido en 1963 en MIT, el Compatible Time-Sharing System fue el primer sistema multiusuario de tiempo compartido y cambió la relación con la computadora. Antes dominaban los procesos por lotes; con CTSS aparecieron los terminales en tiempo real y la posibilidad de desarrollar programas de manera interactiva.
El IBM 7094 que alojaba CTSS ahora parece mínimo, pero en su momento era infraestructura de punta. Según ELIZAGEN, costaba 2,9 millones de dólares, equivalentes a unos 23 millones en 2023, y seguía activo en MIT hasta comienzos de la década de 1970. Ese límite técnico ayuda a leer mejor a ELIZA: un programa conversacional nacido en una máquina así no podía apoyarse en estadísticas masivas ni en entrenamiento sobre corpus gigantes.
Ahí aparece una distancia útil con la IA actual. El rendimiento se discute con bancos de prueba y cargas multimodales como las de MLPerf. ELIZA pertenece a otro régimen técnico: una época en la que la pregunta no era cuántos tokens por segundo podía entregar un sistema, sino si una máquina podía sostener una conversación suficientemente convincente como para desconcertar a un usuario humano.
Un terapeuta sin comprensión
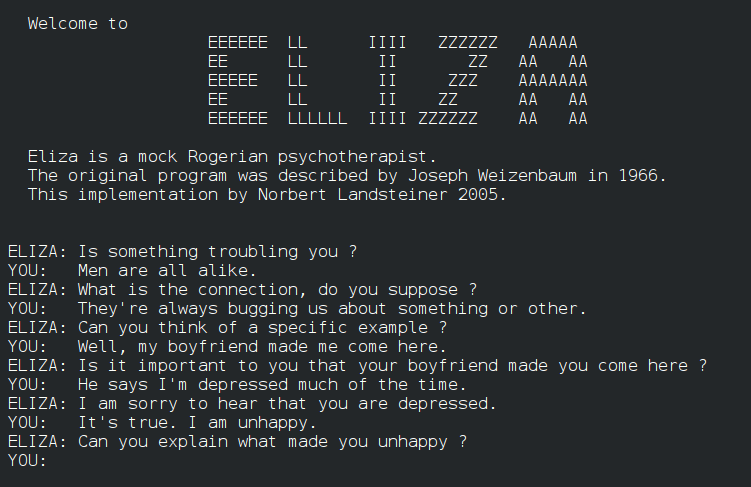
La versión más conocida de ELIZA simulaba a un psicoterapeuta rogeriano. Su truco no era comprender el sentido profundo de una frase, sino detectar palabras clave, reorganizar partes del texto del usuario y devolverlas en forma de pregunta o reformulación. Computer History Museum resume el mecanismo así: respuestas a partir de reglas fijas y repetición de frases del interlocutor para dar impresión de escucha.
Ese procedimiento era simple, pero el efecto cultural fue enorme. Weizenbaum observó que algunas personas proyectaban sobre el programa una comprensión que el sistema no tenía. ELIZA había mostrado que una conversación sintácticamente razonable podía disparar atribuciones psicológicas fuertes incluso cuando detrás sólo había sustitución de patrones.
La anécdota sigue siendo actual porque nombra un problema persistente. El término “chatbot” recién se popularizó en la década de 1990, pero la confusión entre fluidez verbal y entendimiento ya estaba presente en 1966. ELIZA no “pensaba”, no mantenía una representación rica del mundo y no sabía por qué decía lo que decía. Aun así, alcanzó para instalar una intuición durable: hablar con una máquina cambia la forma en que medimos su inteligencia.
Lo que hubo que reconstruir para hacerlo correr
Restaurar ELIZA no consistió en copiar un texto y compilarlo. El equipo tuvo que transcribir a mano páginas que el OCR leía mal, trabajar con una codificación BCD de 6 bits anterior a ASCII y volver a una lógica de columnas heredada de las tarjetas perforadas.
ELIZA usaba SLIP, el Symmetric List Processor que Weizenbaum había creado antes, para gran parte de su procesamiento de listas. Durante la restauración aparecieron tres funciones faltantes que Anthony Hay y Arthur Schwarz tuvieron que reemplazar para completar la ejecución. Aun con esas intervenciones, ELIZAGEN sostiene que el 96% del código proviene de los archivos originales.
El resultado permite algo raro en historia de la informática: no sólo leer el artefacto, sino volver a operarlo. Esa clase de rescate dialoga con otras tareas de preservación digital, desde catálogos de hardware como OpenCHM hasta la recuperación de interfaces, páginas y sistemas cuya lógica se pierde antes que sus soportes físicos.
Lo que deja ver un chatbot de reglas
ELIZA importa menos por nostalgia que por claridad. Su funcionamiento puede seguirse de punta a punta: reglas, guion, límites, entorno operativo y trucos conversacionales. En una época de modelos opacos, esa transparencia se volvió rara. La discusión contemporánea sobre documentación y procedencia de los sistemas de IA repite por otros medios una pregunta antigua: qué sabemos exactamente de la máquina que nos habla.
Por eso el rescate del código original vale como documento técnico y no sólo como reliquia. Muestra que el problema de la conversación artificial empezó mucho antes de los modelos generativos y que una parte de su poder siempre estuvo en el diseño de la interfaz humana. Si una máquina de 36 bits y 32 mil palabras de memoria alcanzó para inducir esa ilusión en 1966, la pregunta histórica no es sólo qué pueden hacer los chatbots actuales, sino cuánto de su efecto sigue dependiendo de una vieja disposición humana a completar con sentido lo que una máquina apenas insinúa.
¿Qué era ELIZA y cómo funcionaba el primer chatbot de la historia?
ELIZA fue creada por Joseph Weizenbaum en el MIT entre 1964 y 1966. No tenía inteligencia ni comprensión: funcionaba con un sistema de reglas y patrones que detectaban palabras clave en el input del usuario y devolvían respuestas predefinidas o reformulaciones de lo que el usuario había dicho. El modo más conocido, DOCTOR, simulaba una sesión de psicoterapia socrática. ELIZA no entendía nada — pero su estructura conversacional era suficiente para que muchos usuarios creyeran estar hablando con alguien que los escuchaba.
¿Cómo se recuperó el código original de ELIZA después de 60 años?
El proyecto ELIZAGEN localizó 53 páginas del código original de ELIZA en los archivos del MIT, escritas en MAD-SLIP para el mainframe IBM 7094 de los años 60. El código fue interpretado y convertido para ejecutarse en hardware moderno. Durante la restauración faltaban tres funciones que los investigadores tuvieron que reconstruir. El resultado final recuperó el 96% del código original y permite volver a operar ELIZA como lo hacían sus usuarios en 1966.
¿Por qué importa estudiar a ELIZA en la era de los chatbots modernos?
ELIZA es transparente de punta a punta: reglas, guion, límites y trucos conversacionales son visibles y rastreables. En una era de modelos opacos, esa claridad tiene valor como documento técnico. ELIZA también ilustra que gran parte del efecto de los chatbots siempre estuvo en el diseño de la interfaz humana, no en la potencia del sistema: una máquina de 36 bits y 32 mil palabras de memoria indujo la ilusión de comprensión en 1966. La pregunta histórica que abre es cuánto del poder de los LLMs actuales sigue dependiendo de esa misma disposición humana a completar con sentido lo que una máquina apenas insinúa.
Fuente original: ELIZAGEN